GrapheneOS es un sistema operativo móvil centrado en la seguridad y la privacidad basado en una versión modificada de Android (AOSP). Para mejorar su protección, integra funciones de seguridad avanzadas, incluido su propio asignador de memoria para libc: malloc endurecido. Diseñado para ser tan robusto como el propio sistema operativo, este asignador busca específicamente proteger contra la corrupción de la memoria.
Este artículo técnico detalla el funcionamiento interno del malloc endurecido y los mecanismos de protección que implementa para prevenir vulnerabilidades comunes de corrupción de memoria. Está destinado a un público técnico, en particular investigadores de seguridad o desarrolladores de exploits, que deseen obtener una comprensión profunda de las partes internas del asignador.
Los análisis y pruebas de este artículo se realizaron en dos dispositivos que ejecutan GrapheneOS:
- Pixel 4a 5G:
google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys - Pixel 9a:
google/tegu/tegu:16/BP2A.250705.008/2025071900:user/release-keys
Los dispositivos fueron rooteados con Magisk 29 para poder utilizar Frida para observar el estado interno de malloc endurecido dentro de los procesos del sistema. El estudio se basó en el código fuente del Repositorio de GitHub de GrapheneOS (commit 7481c8857faf5c6ed8666548d9e92837693de91b).
GrapheneOS
GrapheneOS es un sistema operativo reforzado basado en Android. Como proyecto de código abierto mantenido activamente, se beneficia de actualizaciones frecuentes y la rápida aplicación de parches de seguridad. Toda la información está disponible en el Sitio web de GrapheneOS.
Para proteger eficazmente los procesos que se ejecutan en el dispositivo, GrapheneOS implementa varios mecanismos de seguridad. Las siguientes secciones describen brevemente los mecanismos específicos que contribuyen al endurecimiento de su asignador de memoria.
Espacio de dirección extendido
En los sistemas Android estándar, el espacio de direcciones para los procesos del espacio de usuario está limitado a 39 bits, que van desde 0 to 0x8000000000. En GrapheneOS, este espacio se extiende a 48 bits y, para aprovechar esta extensión, la entropía ASLR también se ha incrementado de 18 a 33 bits. Este detalle es importante ya que malloc endurecido depende en gran medida de mmap por sus estructuras internas y sus asignaciones.
tegu:/ # cat /proc/self/maps
c727739a2000-c727739a9000 rw-p 00000000 00:00 0 [anon:.bss]
c727739a9000-c727739ad000 r--p 00000000 00:00 0 [anon:.bss]
c727739ad000-c727739b1000 rw-p 00000000 00:00 0 [anon:.bss]
c727739b1000-c727739b5000 r--p 00000000 00:00 0 [anon:.bss]
c727739b5000-c727739c1000 rw-p 00000000 00:00 0 [anon:.bss]
e5af7fa30000-e5af7fa52000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d112736be000-d112736c5000 rw-p 00000000 00:00 0 [anon:.bss]
d112736c5000-d112736c9000 r--p 00000000 00:00 0 [anon:.bss]
d112736c9000-d112736cd000 rw-p 00000000 00:00 0 [anon:.bss]
d112736cd000-d112736d1000 r--p 00000000 00:00 0 [anon:.bss]
d112736d1000-d112736dd000 rw-p 00000000 00:00 0 [anon:.bss]
ea0de59be000-ea0de59e1000 rw-p 00000000 00:00 0 [stack]
tegu:/ # cat /proc/self/maps
d71f87043000-d71f8704a000 rw-p 00000000 00:00 0 [anon:.bss]
d71f8704a000-d71f8704e000 r--p 00000000 00:00 0 [anon:.bss]
d71f8704e000-d71f87052000 rw-p 00000000 00:00 0 [anon:.bss]
d71f87052000-d71f87056000 r--p 00000000 00:00 0 [anon:.bss]
d71f87056000-d71f87062000 rw-p 00000000 00:00 0 [anon:.bss]
f69f7c952000-f69f7c974000 rw-p 00000000 00:00 0 [stack]
Generación segura de aplicaciones
En Android estándar, cada aplicación se inicia a través de un fork de la zygote procesar. Este mecanismo, diseñado para acelerar el inicio, tiene una importante consecuencia de seguridad: todas las aplicaciones heredan el mismo espacio de direcciones que zygote. En la práctica, esto significa que las bibliotecas precargadas terminan en direcciones idénticas de una aplicación a otra. Para un atacante, esta previsibilidad facilita eludir la protección ASLR sin necesidad de una fuga de información previa.
Para superar esta limitación, GrapheneOS cambia fundamentalmente este proceso. En lugar de sólo un fork, se lanzan nuevas aplicaciones con exec. Este método crea un espacio de direcciones completamente nuevo y aleatorio para cada proceso, restaurando así la plena eficacia de ASLR. Ya no es posible predecir la ubicación de regiones de memoria remotas. Sin embargo, esta seguridad mejorada tiene un costo: un ligero impacto en el rendimiento del lanzamiento y un mayor consumo de memoria para cada aplicación.
tegu:/ # cat /proc/$(pidof zygote64)/maps | grep libc\.so
d6160aac0000-d6160ab19000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160ab1c000-d6160abbe000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc0000-d6160abc5000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d6160abc8000-d6160abc9000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.android.messaging)/maps | grep libc\.so
d5e4a9c68000-d5e4a9cc1000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9cc4000-d5e4a9d66000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d68000-d5e4a9d6d000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
d5e4a9d70000-d5e4a9d71000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
tegu:/ # cat /proc/$(pidof com.topjohnwu.magisk)/maps | grep libc\.so
dabc42ac5000-dabc42b1e000 r--p 00000000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42b21000-dabc42bc3000 r-xp 0005c000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bc5000-dabc42bca000 r--p 00100000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
dabc42bcd000-dabc42bce000 rw-p 00108000 07:f0 24 /apex/com.android.runtime/lib64/bionic/libc.so
Extensión de etiquetado de memoria (MTE)
Extensión de etiquetado de memoria, o MTE, es una extensión de la arquitectura ARM introducida con Armv8.5. MTE tiene como objetivo evitar que un atacante explote vulnerabilidades de corrupción de memoria. Esta protección se basa en un mecanismo de etiquetado de regiones de memoria.
Durante una asignación, una etiqueta de 4 bits se asocia con la región asignada y se almacena en los bits superiores del puntero. Para acceder a los datos, tanto la dirección como la etiqueta deben ser correctas. Si la etiqueta es incorrecta, se genera una excepción. Este mecanismo permite la detección y bloqueo de vulnerabilidades como lecturas/escrituras fuera de límites y uso después de la liberación.
Por ejemplo, se podría detectar la escritura fuera de límites en el siguiente código C, dependiendo de la implementación del asignador con MTE:
char* ptr = malloc(8);
ptr[16] = 12; // oob write, this tag is not valid for the areaDado que MTE es una característica que ofrece la CPU, es necesario que el hardware sea compatible. Este es el caso de todos los teléfonos inteligentes Google Pixel desde el Pixel 8. Para obtener más información, consulte la Documentación ARM.
Malloc endurecido por lo tanto utiliza MTE en teléfonos inteligentes compatibles para evitar este tipo de corrupción de memoria.
Para beneficiarse de MTE, se debe compilar un binario con las banderas apropiadas. A los efectos de este artículo, se agregaron las siguientes banderas a la Application.mk archivo de nuestros binarios de prueba para habilitar MTE.
APP_CFLAGS := -fsanitize=memtag -fno-omit-frame-pointer -march=armv8-a+memtag
APP_LDFLAGS := -fsanitize=memtag -march=armv8-a+memtagLa Documentación de Android proporciona toda la información necesaria para crear una aplicación compatible con MTE.
Malloc endurecido depende en gran medida de MTE agregando etiquetas a sus asignaciones. Tenga en cuenta que solo las pequeñas asignaciones (menos de 0x20000 bytes) están etiquetadas.
Arquitectura de malloc endurecido
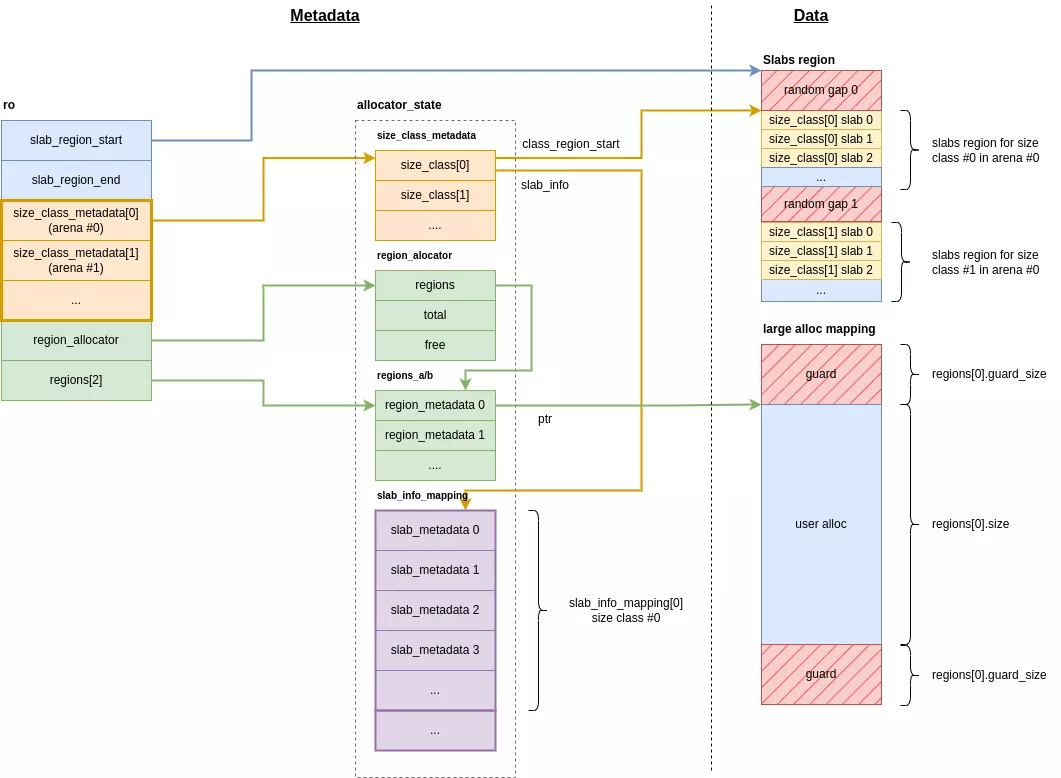
Para mejorar la seguridad, malloc endurecido aísla los metadatos de los datos del usuario en regiones de memoria separadas, manteniéndolos principalmente dentro de dos estructuras principales:
ro: la estructura principal en la.bsssección de libc.allocator_state: una estructura grande que agrupa todos los metadatos para los diferentes tipos de asignación. Su región de memoria se reserva sólo una vez en el momento de la inicialización.
Similar a jemalloc, malloc endurecido divide los hilos en arenas, y cada arena gestiona sus propias asignaciones. Esto implica que la memoria asignada en una arena no puede ser administrada ni liberada por otra arena. Sin embargo, no existe una estructura de datos explícita para definir estos ámbitos; su existencia es implícita y afecta principalmente al tamaño de ciertas matrices internas.
Aunque el concepto de arena está presente en el código fuente, el análisis de los binarios libc de los dispositivos de prueba reveló que malloc endurecido fue compilado para utilizar una sola arena. Como resultado, todos los subprocesos comparten el mismo conjunto de metadatos de asignación.
Estructura ro
La estructura ro es la estructura de metadatos principal del asignador. Está contenida dentro de la .bss sección de libc y consta de los siguientes atributos:
static union {
struct {
void *slab_region_start;
void *_Atomic slab_region_end;
struct size_class *size_class_metadata[N_ARENA];
struct region_allocator *region_allocator;
struct region_metadata *regions[2];
#ifdef USE_PKEY
int metadata_pkey;
#endif
#ifdef MEMTAG
bool is_memtag_disabled;
#endif
};
char padding[PAGE_SIZE];
} ro __attribute__((aligned(PAGE_SIZE)));slab_region_start: El inicio del área de memoria que contiene las regiones para pequeñas asignaciones.slab_region_end: El final del área de memoria que contiene las regiones para pequeñas asignaciones.size_class_metadata[N_ARENA]: Una matriz de punteros a los metadatos para pequeñas asignaciones, por arena.region_allocator: Un puntero a la estructura de gestión para grandes asignaciones.regions[2]: Un puntero a las tablas hash que hacen referencia a las grandes asignaciones.
allocator_state
Esta estructura contiene todos los metadatos utilizados para tanto pequeñas como grandes asignaciones. Se asigna solo una vez cuando el asignador se inicializa y está aislado por páginas de guarda. Su tamaño es fijo y se calcula en función del número máximo de asignaciones que el asignador puede manejar.
struct __attribute__((aligned(PAGE_SIZE))) allocator_state {
struct size_class size_class_metadata[N_ARENA][N_SIZE_CLASSES];
struct region_allocator region_allocator;
// padding until next page boundary for mprotect
struct region_metadata regions_a[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct region_metadata regions_b[MAX_REGION_TABLE_SIZE] __attribute__((aligned(PAGE_SIZE)));
// padding until next page boundary for mprotect
struct slab_info_mapping slab_info_mapping[N_ARENA][N_SIZE_CLASSES];
// padding until next page boundary for mprotect
};size_class_metadata[N_ARENA][N_SIZE_CLASSES]: Una matriz desize_classestructuras que contienen los metadatos para pequeñas asignaciones para cada clase.region_allocator: Los metadatos para las grandes regiones de asignaciones.regions_a/b[MAX_REGION_TABLE_SIZE]: Una tabla hash que agrupa información sobre las grandes asignaciones.slab_info_mapping: Los metadatos de las losas de pequeñas asignaciones.
Datos del usuario
Malloc endurecido almacena datos de usuario en dos tipos de regiones, separadas de sus metadatos:
- Región de losas: un área muy grande reservada solo una vez en el momento de la inicialización, que contiene las losas para pequeñas asignaciones. Se inicializa en la función
init_slow_pathy su dirección de inicio se almacena enro.slab_region_start. - Grandes regiones: áreas reservadas dinámicamente que contienen los datos para grandes asignaciones. Cada una de estas regiones contiene sólo una única gran asignación.
Asignaciones
Hay dos tipos de asignaciones en malloc endurecido: pequeñas asignaciones y grandes asignaciones.
Pequeñas asignaciones
Clases de tamaño/contenedores
Las asignaciones pequeñas se clasifican por tamaño en clases de tamaño, también conocido como contenedores. Malloc endurecido utiliza 49 de estas clases, que están indexadas por tamaño creciente y representadas por la size_class estructura:
| Clase de tamaño | Tamaño total del contenedor | Tamaño disponible | Ranuras | Tamaño de la losa | Losas máximas | Tamaño de las cuarentenas (aleatorias / FIFO) |
|---|---|---|---|---|---|---|
| 0 | 0x10 | 0x10 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 1 | 0x10 | 0x8 | 256 | 0x1000 | 8388608 | 8192 / 8192 |
| 2 | 0x20 | 0x18 | 128 | 0x1000 | 8388608 | 4096 / 4096 |
| 3 | 0x30 | 0x28 | 85 | 0x1000 | 8388608 | 4096 / 4096 |
| 4 | 0x40 | 0x38 | 64 | 0x1000 | 8388608 | 2048 / 2048 |
| 5 | 0x50 | 0x48 | 51 | 0x1000 | 8388608 | 2048 / 2048 |
| 6 | 0x60 | 0x58 | 42 | 0x1000 | 8388608 | 2048 / 2048 |
| 7 | 0x70 | 0x68 | 36 | 0x1000 | 8388608 | 2048 / 2048 |
| 8 | 0x80 | 0x78 | 64 | 0x2000 | 4194304 | 1024 / 1024 |
| 9 | 0xa0 | 0x98 | 51 | 0x2000 | 4194304 | 1024 / 1024 |
| 10 | 0xc0 | 0xb8 | 64 | 0x3000 | 2796202 | 1024 / 1024 |
| 11 | 0xe0 | 0xd8 | 54 | 0x3000 | 2796202 | 1024 / 1024 |
| 12 | 0x100 | 0xf8 | 64 | 0x4000 | 2097152 | 512 / 512 |
| 13 | 0x140 | 0x138 | 64 | 0x5000 | 1677721 | 512 / 512 |
| 14 | 0x180 | 0x178 | 64 | 0x6000 | 1398101 | 512 / 512 |
| 15 | 0x1c0 | 0x1b8 | 64 | 0x7000 | 1198372 | 512 / 512 |
| 16 | 0x200 | 0x1f8 | 64 | 0x8000 | 1048576 | 256 / 256 |
| 17 | 0x280 | 0x278 | 64 | 0xa000 | 838860 | 256 / 256 |
| 18 | 0x300 | 0x2f8 | 64 | 0xc000 | 699050 | 256 / 256 |
| 19 | 0x380 | 0x378 | 64 | 0xe000 | 599186 | 256 / 256 |
| 20 | 0x400 | 0x3f8 | 64 | 0x10000 | 524288 | 128 / 128 |
| 21 | 0x500 | 0x4f8 | 16 | 0x5000 | 1677721 | 128 / 128 |
| 22 | 0x600 | 0x5f8 | 16 | 0x6000 | 1398101 | 128 / 128 |
| 23 | 0x700 | 0x6f8 | 16 | 0x7000 | 1198372 | 128 / 128 |
| 24 | 0x800 | 0x7f8 | 16 | 0x8000 | 1048576 | 64 / 64 |
| 25 | 0xa00 | 0x9f8 | 8 | 0x5000 | 1677721 | 64 / 64 |
| 26 | 0xc00 | 0xbf8 | 8 | 0x6000 | 1398101 | 64 / 64 |
| 27 | 0xe00 | 0xdf8 | 8 | 0x7000 | 1198372 | 64 / 64 |
| 28 | 0x1000 | 0xff8 | 8 | 0x8000 | 1048576 | 32 / 32 |
| 29 | 0x1400 | 0x13f8 | 8 | 0xa000 | 838860 | 32 / 32 |
| 30 | 0x1800 | 0x17f8 | 8 | 0xc000 | 699050 | 32 / 32 |
| 31 | 0x1c00 | 0x1bf8 | 8 | 0xe000 | 599186 | 32 / 32 |
| 32 | 0x2000 | 0x1ff8 | 8 | 0x10000 | 524288 | 16 / 16 |
| 33 | 0x2800 | 0x27f8 | 6 | 0xf000 | 559240 | 16 / 16 |
| 34 | 0x3000 | 0x2ff8 | 5 | 0xf000 | 559240 | 16 / 16 |
| 35 | 0x3800 | 0x37f8 | 4 | 0xe000 | 599186 | 16 / 16 |
| 36 | 0x4000 | 0x3ff8 | 4 | 0x10000 | 524288 | 8 / 8 |
| 37 | 0x5000 | 0x4ff8 | 1 | 0x5000 | 1677721 | 8 / 8 |
| 38 | 0x6000 | 0x5ff8 | 1 | 0x6000 | 1398101 | 8 / 8 |
| 39 | 0x7000 | 0x6ff8 | 1 | 0x7000 | 1198372 | 8 / 8 |
| 40 | 0x8000 | 0x7ff8 | 1 | 0x8000 | 1048576 | 4 / 4 |
| 41 | 0xa000 | 0x9ff8 | 1 | 0xa000 | 838860 | 4 / 4 |
| 42 | 0xc000 | 0xbff8 | 1 | 0xc000 | 699050 | 4 / 4 |
| 43 | 0xe000 | 0xdff8 | 1 | 0xe000 | 599186 | 4 / 4 |
| 44 | 0x10000 | 0xfff8 | 1 | 0x10000 | 524288 | 2 / 2 |
| 45 | 0x14000 | 0x13ff8 | 1 | 0x14000 | 419430 | 2 / 2 |
| 46 | 0x18000 | 0x17ff8 | 1 | 0x18000 | 349525 | 2 / 2 |
| 47 | 0x1c000 | 0x1bff8 | 1 | 0x1c000 | 299593 | 2 / 2 |
| 48 | 0x20000 | 0x1fff8 | 1 | 0x20000 | 262144 | 1 / 1 |
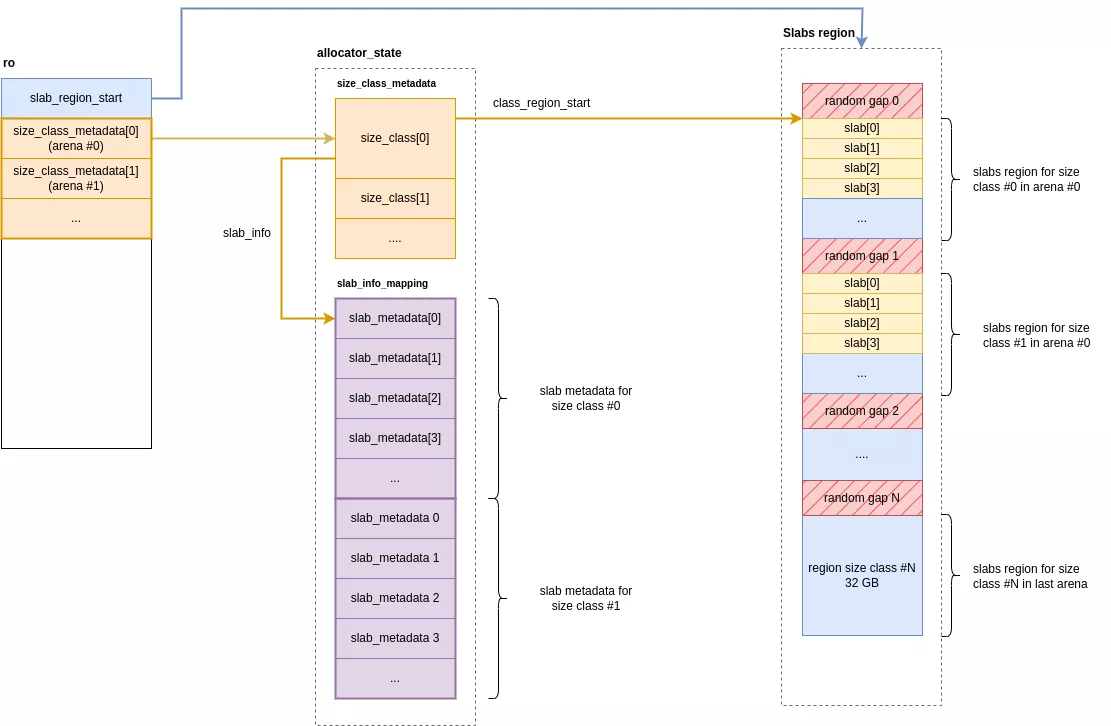
Dentro de cada arena, un conjunto de 49 size_class entradas mantienen los metadatos para cada clase de tamaño. Para cada clase, el asignador reserva una región de memoria dedicada para almacenar sus asignaciones correspondientes. Esta región está segmentada en losas, que a su vez se subdividen en ranuras. Cada ranura corresponde a un único fragmento de memoria devuelto al usuario.
Las regiones de todas las clases se reservan de forma contigua en la memoria cuando se inicializa el asignador. Cada región ocupa 32 GiB de memoria en un desplazamiento aleatorio dentro de un área de 64 GiB. Las áreas vacías antes y después de la región actúan como guardias alineados con las páginas de un tamaño aleatorio.
Para resumir:
- Se asigna una región de 32 GiB por clase de tamaño.
- Está encapsulado en un desplazamiento aleatorio dentro de una zona del doble de su tamaño (64 GiB).
- Las zonas de 64 GiB son contiguas y están ordenadas por clase de tamaño creciente.
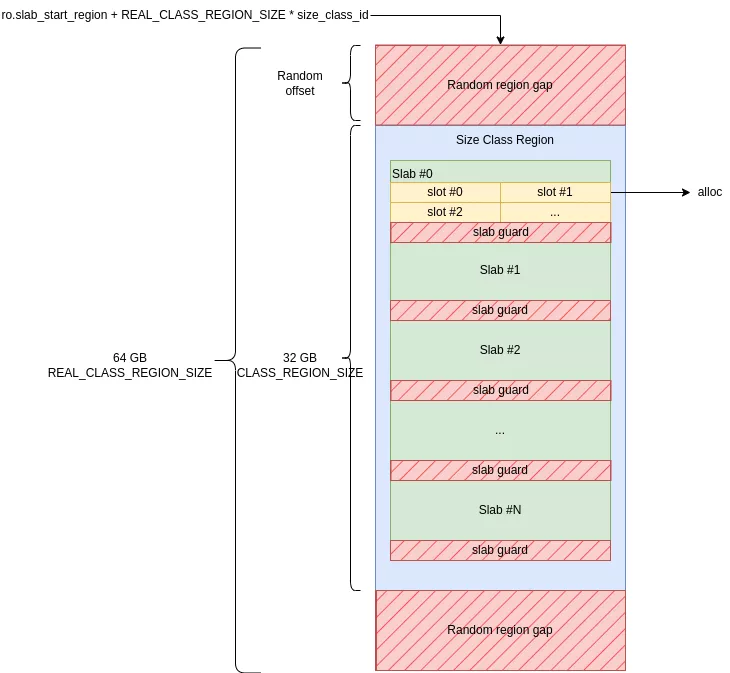
El tamaño del área de memoria contigua reservada durante la inicialización es N_ARENA * 49 * 64 GiB. En los dispositivos de prueba, que utilizan una única arena, esto equivale a 0x31000000000 bytes (~3 TB). De forma predeterminada, estas páginas están protegidas con PROT_NONE, lo que significa que no están respaldados por la memoria física. Esta protección se cambia a Leer/Escribir (RW) a pedido para páginas específicas según se necesiten asignaciones.
// CONFIG_EXTENDED_SIZE_CLASSES := true
// CONFIG_LARGE_SIZE_CLASSES := true
// CONFIG_CLASS_REGION_SIZE := 34359738368 # 32GiB
// CONFIG_N_ARENA := 1
#define CLASS_REGION_SIZE (size_t)CONFIG_CLASS_REGION_SIZE
#define REAL_CLASS_REGION_SIZE (CLASS_REGION_SIZE * 2)
#define ARENA_SIZE (REAL_CLASS_REGION_SIZE * N_SIZE_CLASSES)
static const size_t slab_region_size = ARENA_SIZE * N_ARENA; // 0x31000000000 on Pixel 4a 5G and Pixel 9a
// ...
COLD static void init_slow_path(void) {
// ...
// Create a big mapping with MTE enabled
ro.slab_region_start = memory_map_tagged(slab_region_size);
if (unlikely(ro.slab_region_start == NULL)) {
fatal_error("failed to allocate slab region");
}
void *slab_region_end = (char *)ro.slab_region_start + slab_region_size;
memory_set_name(ro.slab_region_start, slab_region_size, "malloc slab region gap");
// ...
}
Cada clase de tamaño (o contenedor) está representada por una size_class estructura, una estructura relativamente grande que contiene toda la información relevante para esa clase.
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
struct mutex lock;
void *class_region_start;
struct slab_metadata *slab_info;
struct libdivide_u32_t size_divisor;
struct libdivide_u64_t slab_size_divisor;
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// slabs with at least one allocated slot and at least one free slot
//
// LIFO doubly-linked list
struct slab_metadata *partial_slabs;
// slabs without allocated slots that are cached for near-term usage
//
// LIFO singly-linked list
struct slab_metadata *empty_slabs;
size_t empty_slabs_total; // length * slab_size
// slabs without allocated slots that are purged and memory protected
//
// FIFO singly-linked list
struct slab_metadata *free_slabs_head;
struct slab_metadata *free_slabs_tail;
struct slab_metadata *free_slabs_quarantine[FREE_SLABS_QUARANTINE_RANDOM_LENGTH];
#if CONFIG_STATS
u64 nmalloc; // may wrap (per jemalloc API)
u64 ndalloc; // may wrap (per jemalloc API)
size_t allocated;
size_t slab_allocated;
#endif
struct random_state rng;
size_t metadata_allocated;
size_t metadata_count;
size_t metadata_count_unguarded;
};
Sus principales miembros son:
class_region_start: dirección de inicio de la región de memoria para las losas de esta clase.slab_info: puntero al comienzo de la matriz de metadatos de la losa.quarantine_random,quarantine_queue: conjuntos de punteros a asignaciones actualmente en cuarentena (consulte la sección sobre cuarentenas).partial_slabs: una pila de metadatos para losas parcialmente rellenas.free_slabs_{head, tail}: una cola de metadatos para losas vacías.
Los metadatos de la losa se guardan en la slab_metadata estructura. Para cualquier clase de tamaño dada, estas estructuras forman una matriz contigua, accesible a través del size_class->slab_info puntero. El diseño de esta matriz de metadatos refleja directamente el diseño de las losas en su región de memoria. Este diseño permite una búsqueda directa: los metadatos de una losa se pueden encontrar simplemente usando el índice de la losa para acceder a la matriz.
struct slab_metadata {
u64 bitmap[4];
struct slab_metadata *next;
struct slab_metadata *prev;
#if SLAB_CANARY
u64 canary_value;
#endif
#ifdef SLAB_METADATA_COUNT
u16 count;
#endif
#if SLAB_QUARANTINE
u64 quarantine_bitmap[4];
#endif
#ifdef HAS_ARM_MTE
// arm_mte_tags is used as a u4 array (MTE tags are 4-bit wide)
//
// Its size is calculated by the following formula:
// (MAX_SLAB_SLOT_COUNT + 2) / 2
// MAX_SLAB_SLOT_COUNT is currently 256, 2 extra slots are needed for branchless handling of
// edge slots in tag_and_clear_slab_slot()
//
// It's intentionally placed at the end of struct to improve locality: for most size classes,
// slot count is far lower than MAX_SLAB_SLOT_COUNT.
u8 arm_mte_tags[129];
#endif
};
bitmap[4]: seguimiento de mapa de bits qué ranuras de la losa están en uso.next, prev: punteros a los elementos siguientes/anteriores cuando la estructura pertenece a una lista enlazada (por ejemplo, en la pila de losas parcialmente utilizadassize_class->partial_slabs).canary_value: valor canario agregado al final de cada ranura dentro de la losa (solo en dispositivos que no sean MTE). Este valor se verifica enfreepara detectar desbordamientos de búfer.arm_mte_tags[129]: Etiquetas MTE actualmente en uso por ranura.
Alloc
Primero, el tamaño real a asignar se calcula agregando 8 bytes al tamaño solicitado por el usuario. Estos bytes adicionales se llenan con un canario y se colocan inmediatamente después de los datos. Una asignación se considera "pequeña" sólo si este nuevo tamaño es menor que 0x20000 bytes (131.072 bytes). A continuación, se debe recuperar una ranura libre de una losa siguiendo estos pasos:
- Recuperar la arena: la arena actual se obtiene del almacenamiento local del hilo.
- Obtener metadatos de clase de tamaño: los metadatos para la clase de tamaño correspondiente (la
size_classestructura) se recupera utilizandoro.size_class_metadata[arena][size_class], dondearenaes el número de la arena ysize_classes el índice calculado a partir del tamaño de la asignación. - Encuentra una losa con una ranura libre:
- si existe una losa parcialmente rellena (
size_class->partial_slabs != NULL), se utiliza esta losa. - de lo contrario, si hay al menos una losa vacía disponible (
size_class->empty_slabs != NULL), se utiliza la primera losa de esta lista. - si no hay losa disponible, se asigna una nueva (asignando una
slab_metadataestructura que utiliza laalloc_metadata()función). Entre cada losa real se reserva una losa de "guardia". - Seleccione una ranura libre aleatoria: se elige una ranura libre aleatoriamente desde dentro de la losa seleccionada. Las ranuras ocupadas están marcadas por
1s en elslab_metadata->bitmap. - Seleccione una etiqueta MTE: se elige una nueva etiqueta MTE para la ranura, asegurándose de que sea diferente de las etiquetas adyacentes para evitar desbordamientos lineales simples. Se excluyen las siguientes etiquetas:
- la etiqueta de la ranura anterior.
- la etiqueta de la siguiente ranura.
- la etiqueta antigua de la ranura actualmente seleccionada.
- el
RESERVED_TAG(0), que se utiliza para asignaciones liberadas. - Establecer protecciones:
- En dispositivos sin MTE, el canario (que es común a todas las ranuras de la losa) se escribe en los últimos 8 bytes de la ranura.
- En dispositivos habilitados para MTE, estos 8 bytes se establecen en 0.
- Devuelve la dirección de la ranura, ahora etiquetada con la etiqueta MTE.
Para una asignación pequeña, la dirección devuelta por malloc es un puntero a una ranura con una etiqueta MTE de 4 bits codificada en sus bits más significativos. Los punteros a continuación, recuperados de llamadas sucesivas a malloc(8), están ubicados en la misma losa pero con desplazamientos aleatorios y tienen diferentes etiquetas MTE.
ptr[0] = 0xa00cd70ad02a930
ptr[1] = 0xf00cd70ad02ac50
ptr[2] = 0x300cd70ad02a2f0
ptr[3] = 0x900cd70ad02a020
ptr[4] = 0x300cd70ad02ac90
ptr[5] = 0x700cd70ad02a410
ptr[6] = 0xc00cd70ad02a3c0
ptr[7] = 0x500cd70ad02a3d0
ptr[8] = 0xf00cd70ad02a860
ptr[9] = 0x600cd70ad02ad20Si se produce un desbordamiento, un SIGSEGV/SEGV_MTESERR se genera una excepción que indica que se accedió a un área protegida por MTE con una etiqueta incorrecta. En GrapheneOS, esto hace que la aplicación finalice y envía un registro de fallas a logcat.
07-23 11:32:19.948 4169 4169 F DEBUG : Cmdline: /data/local/tmp/bin
07-23 11:32:19.948 4169 4169 F DEBUG : pid: 4165, tid: 4165, name: bin >>> /data/local/tmp/bin <<<<
07-23 11:32:19.948 4169 4169 F DEBUG : uid: 2000
07-23 11:32:19.949 4169 4169 F DEBUG : tagged_addr_ctrl: 000000000007fff3 (PR_TAGGED_ADDR_ENABLE, PR_MTE_TCF_SYNC, mask 0xfffe)
07-23 11:32:19.949 4169 4169 F DEBUG : pac_enabled_keys: 000000000000000f (PR_PAC_APIAKEY, PR_PAC_APIBKEY, PR_PAC_APDAKEY, PR_PAC_APDBKEY)
07-23 11:32:19.949 4169 4169 F DEBUG : signal 11 (SIGSEGV), code 9 (SEGV_MTESERR), fault addr 0x0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x0 0800d541414042c0 x1 0000d84c01173140 x2 0000000000000015 x3 0000000000000014
07-23 11:32:19.949 4169 4169 F DEBUG : x4 0000b1492c0f16b5 x5 0300d6f2d01ea99b x6 0000000000000029 x7 203d207972742029
07-23 11:32:19.949 4169 4169 F DEBUG : x8 5dde6df273e81100 x9 5dde6df273e81100 x10 0000000000001045 x11 0000000000001045
07-23 11:32:19.949 4169 4169 F DEBUG : x12 0000f2dbd10c1ca4 x13 0000000000000000 x14 0000000000000001 x15 0000000000000020
07-23 11:32:19.949 4169 4169 F DEBUG : x16 0000d84c0116e228 x17 0000d84c010faf50 x18 0000d84c1eb38000 x19 0500d541414042c0
07-23 11:32:19.949 4169 4169 F DEBUG : x20 0000000000001e03 x21 0000b1492c0f16e8 x22 0800d541414042c0 x23 0000000000000001
07-23 11:32:19.949 4169 4169 F DEBUG : x24 0000d541414042c0 x25 0000000000000000 x26 0000000000000000 x27 0000000000000000
07-23 11:32:19.949 4169 4169 F DEBUG : x28 0000000000000000 x29 0000f2dbd10c1f10
07-23 11:32:19.949 4169 4169 F DEBUG : lr 002bb1492c0f2ba0 sp 0000f2dbd10c1f10 pc 0000b1492c0f2ba4 pst 0000000060001000
Free
Para liberar una pequeña asignación, el asignador primero determina su índice de clase de tamaño a partir del puntero. Este índice le permite localizar los metadatos relevantes y la región de memoria donde residen los datos. La función slab_size_class realiza este cálculo inicial.
static struct slab_size_class_info slab_size_class(const void *p) {
size_t offset = (const char *)p - (const char *)ro.slab_region_start;
unsigned arena = 0;
if (N_ARENA > 1) {
arena = offset / ARENA_SIZE;
offset -= arena * ARENA_SIZE;
}
return (struct slab_size_class_info){arena, offset / REAL_CLASS_REGION_SIZE};
}
Con este índice, ahora denominado class_id, es posible recopilar varios detalles sobre la losa que contiene la asignación:
size_classestructura:size_class *c = &ro.size_class_metadata[size_class_info.arena][class_id]- Tamaño de asignación: el tamaño de esta clase se encuentra usando la
size_classestabla de búsqueda:size_t size = size_classes[class_id] - Ranuras por losa: el número de ranuras se encuentra utilizando la
size_class_slotstabla de búsqueda:slots = size_class_slots[class_id] - Tamaño de la losa:
slab_size = page_align(slots * size) - Metadatos de losa actuales:
offset = (const char *)p - (const char *)c->class_region_startindex = offset / slab_sizeslab_metadata = c->slab_info + index
Con esta información, el asignador puede identificar la dirección base de la losa y determinar el índice y el desplazamiento de la ranura específica dentro de esa losa utilizando la función get_slab().
static void *get_slab(const struct size_class *c, size_t slab_size, const struct slab_metadata *metadata) {
size_t index = metadata - c->slab_info;
return (char *)c->class_region_start + (index * slab_size);
}
Luego se deduce la dirección de la ranura con la fórmula slot = (const char*)slab - p, al igual que su índice: slot_index = ((const char*)slab - slot) / slots.
Una vez identificada la ranura, se realizan una serie de comprobaciones cruciales de seguridad e integridad para validar la free operación:
- Alineación del puntero: el asignador verifica que el puntero esté perfectamente alineado con el inicio de una ranura. Cualquier desalineación indica algún tipo de corrupción y la operación se aborta inmediatamente.
- Estado de la ranura: luego verifica los metadatos de la losa para confirmar que la ranura esté marcada actualmente como "en uso".
- Verificación canaria: se verifica la integridad del canario de 8 bytes al final de la ranura. Una diferencia clave con el scudo es que este canario se comparte en toda la losa. Esto significa que una pérdida de memoria de una ranura podría, en teoría, permitir a un atacante falsificar un canario válido para otra ranura y evitar un bloqueo en caso de un
free. - Invalidación de etiqueta MTE: la etiqueta MTE de la ranura se restablece al valor reservado (0), invalidando efectivamente el puntero original y evitando el acceso al puntero colgante.
- Puesta a cero: la memoria de la ranura se borra por completo al ponerla a cero.
Si se detecta un canario no válido, un abort se llama con el siguiente mensaje:
07-23 02:14:09.559 7610 7610 F libc : hardened_malloc: fatal allocator error: canary corrupted
07-23 02:14:09.559 7610 7610 F libc : Fatal signal 6 (SIGABRT), code -1 (SI_QUEUE) in tid 7610 (bin), pid 7610 (bin)
07-23 02:14:09.775 7614 7614 F DEBUG : *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
07-23 02:14:09.775 7614 7614 F DEBUG : Build fingerprint: 'google/bramble/bramble:14/UP1A.231105.001.B2/2025021000:user/release-keys'
07-23 02:14:09.776 7614 7614 F DEBUG : Revision: 'MP1.0'
07-23 02:14:09.776 7614 7614 F DEBUG : ABI: 'arm64'
07-23 02:14:09.776 7614 7614 F DEBUG : Timestamp: 2025-07-23 02:14:09.603643955+0200
07-23 02:14:09.776 7614 7614 F DEBUG : Process uptime: 1s
07-23 02:14:09.776 7614 7614 F DEBUG : Cmdline: /data/local/tmp/bin
07-23 02:14:09.776 7614 7614 F DEBUG : pid: 7610, tid: 7610, name: bin >>> /data/local/tmp/bin <<<<
07-23 02:14:09.776 7614 7614 F DEBUG : uid: 2000
07-23 02:14:09.776 7614 7614 F DEBUG : signal 6 (SIGABRT), code -1 (SI_QUEUE), fault addr --------
07-23 02:14:09.776 7614 7614 F DEBUG : Abort message: 'hardened_malloc: fatal allocator error: canary corrupted'
07-23 02:14:09.776 7614 7614 F DEBUG : x0 0000000000000000 x1 0000000000001dba x2 0000000000000006 x3 0000ea4a84242960
07-23 02:14:09.776 7614 7614 F DEBUG : x4 716e7360626e6b6b x5 716e7360626e6b6b x6 716e7360626e6b6b x7 7f7f7f7f7f7f7f7f
07-23 02:14:09.777 7614 7614 F DEBUG : x8 00000000000000f0 x9 0000cf1d482da2a0 x10 0000000000000001 x11 0000cf1d48331980
07-23 02:14:09.777 7614 7614 F DEBUG : x12 0000000000000004 x13 0000000000000033 x14 0000cf1d482da118 x15 0000cf1d482da050
07-23 02:14:09.777 7614 7614 F DEBUG : x16 0000cf1d483971e0 x17 0000cf1d48383650 x18 0000cf1d6fe40000 x19 0000000000001dba
07-23 02:14:09.777 7614 7614 F DEBUG : x20 0000000000001dba x21 00000000ffffffff x22 0000cc110ff0d150 x23 0000000000000000
07-23 02:14:09.777 7614 7614 F DEBUG : x24 0000000000000001 x25 0000cf0f4a421300 x26 0000000000000000 x27 0000cf0f4a421328
07-23 02:14:09.777 7614 7614 F DEBUG : x28 0000cf0f7ba30000 x29 0000ea4a842429e0
07-23 02:14:09.777 7614 7614 F DEBUG : lr 0000cf1d4831a9f8 sp 0000ea4a84242940 pc 0000cf1d4831aa24 pst 0000000000001000
Finalmente, el espacio no está disponible de inmediato. En cambio, se pone en cuarentena para retrasar su reutilización, una defensa clave contra uso después de la liberación vulnerabilidades.
Cuarentenas
Cada clase de asignación utiliza un sistema de cuarentena de dos etapas para sus espacios liberados. Cuando se libera una asignación, no está inmediatamente disponible para su reutilización, sino que pasa a través de dos áreas de retención distintas:
- Una cuarentena aleatoria: una matriz de tamaño fijo donde las ranuras entrantes reemplazan una ranura existente elegida al azar.
- Una cuarentena en cola: una cola de primero en entrar, primero en salir que recibe espacios expulsados de la cuarentena aleatoria.
Cuando una ranura ingresa a la cuarentena aleatoria, sobrescribe una entrada seleccionada aleatoriamente. Esa entrada expulsada luego es empujada a la cola de cuarentena. Luego, la cola expulsa su elemento más antiguo, que finalmente queda disponible para nuevas asignaciones. Todo este proceso se gestiona dentro de cada clase size_class estructura:
struct __attribute__((aligned(CACHELINE_SIZE))) size_class {
// ...
#if SLAB_QUARANTINE_RANDOM_LENGTH > 0
void *quarantine_random[SLAB_QUARANTINE_RANDOM_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
#endif
#if SLAB_QUARANTINE_QUEUE_LENGTH > 0
void *quarantine_queue[SLAB_QUARANTINE_QUEUE_LENGTH << (MAX_SLAB_SIZE_CLASS_SHIFT - MIN_SLAB_SIZE_CLASS_SHIFT)];
size_t quarantine_queue_index;
#endif
// ...
}
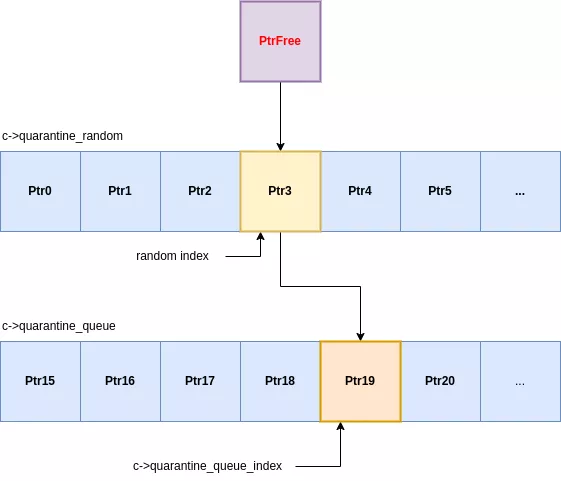
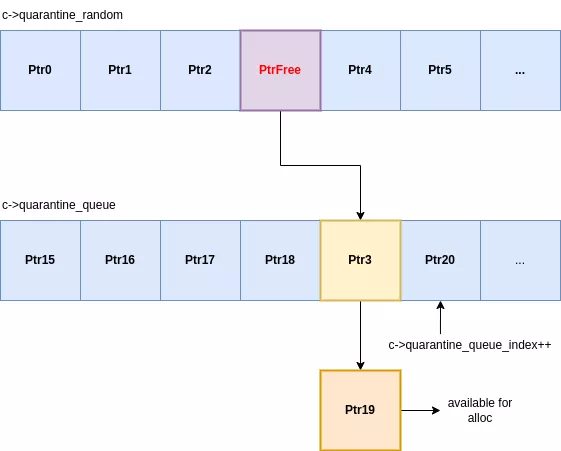
Este diseño supone un cambio significativo respecto de los asignadores tradicionales, que utilizan una lista independiente LIFO (último en entrar, primero en salir) simple. En malloc endurecido, el último elemento liberado casi nunca es el primero en reasignarse. Para recuperar una ranura específica, un atacante debe activar lo suficiente free operaciones para recorrer con éxito su espacio objetivo tanto a través de la cuarentena aleatoria como de la cuarentena en cola. Esto añade una capa sustancial de no determinismo y complejidad a uso después de la liberación exploits, proporcionando una defensa robusta incluso en dispositivos que carecen de MTE.
Dado que el asignador no tiene una lista independiente, la forma más sencilla de forzar una reutilización es encadenar llamadas a malloc y free. El número de free operaciones requeridas dependen de los tamaños de cuarentena para esa clase de tamaño específica.
void reuse(void* target_ptr, size_t size) {
free(target_ptr);
for (int i = 0; ; i++) {
void* new_ptr = malloc(size);
if (untag(target_ptr) == untag(new_ptr)) {
printf("REUSED [size = 0x%x] target_ptr @ %p (new_ptr == %p) try = %d\n", size, target_ptr, new_ptr, i);
break;
}
free(new_ptr);
}
}
Para una asignación de 8 bytes, ambas cuarentenas contienen 8.192 elementos. Si bien esto implica que se necesitan al menos 8.192 liberaciones, la naturaleza aleatoria de la primera etapa significa que el número real es mucho mayor. En las pruebas, se requirió un promedio de ~19.000 free operaciones para recuperar una ranura de forma fiable. La doble cuarentena convierte la reutilización predecible de la memoria en una lotería costosa y poco confiable, lo que obstaculiza gravemente un vector de explotación común.
Grandes asignaciones
Alloc
A diferencia de las asignaciones pequeñas, las asignaciones grandes no se clasifican por tamaño en regiones previamente reservadas. En cambio, el asignador los mapea según demanda. Este mecanismo es el único en malloc endurecido que crea asignaciones de memoria dinámicamente. El tamaño total del mapeo depende de varios factores:
- Tamaño alineado: calculado en
get_large_size_classalineando el tamaño solicitado con clases predefinidas, continuando con los pequeños tamaños de asignación. - Tamaño de la página de guardia: un número aleatorio de páginas que preceden y siguen a la asignación real.
static size_t get_large_size_class(size_t size) {
if (CONFIG_LARGE_SIZE_CLASSES) {
// Continue small size class growth pattern of power of 2 spacing classes:
//
// 4 KiB [20 KiB, 24 KiB, 28 KiB, 32 KiB]
// 8 KiB [40 KiB, 48 KiB, 54 KiB, 64 KiB]
// 16 KiB [80 KiB, 96 KiB, 112 KiB, 128 KiB]
// 32 KiB [160 KiB, 192 KiB, 224 KiB, 256 KiB]
// 512 KiB [2560 KiB, 3 MiB, 3584 KiB, 4 MiB]
// 1 MiB [5 MiB, 6 MiB, 7 MiB, 8 MiB]
// etc.
return get_size_info(max(size, (size_t)PAGE_SIZE)).size;
}
return page_align(size);
}
Una vez determinados estos tamaños, el asignador crea un mapeo mediante mmap() para su total combinado. Las áreas de guardia antes y después de que se mapeen los datos PROT_NONE, mientras se mapea la región de datos en sí PROT_READ|PROT_WRITE. Este uso de páginas de protección de tamaño aleatorio significa que dos grandes asignaciones del mismo tamaño solicitado ocuparán áreas mapeadas de diferentes tamaños totales, agregando una capa de no determinismo.
void *allocate_pages_aligned(size_t usable_size, size_t alignment, size_t guard_size, const char *name) {
//...
// Compute real mapped size = alloc_size + 2 * guard_size
size_t real_alloc_size;
if (unlikely(add_guards(alloc_size, guard_size, &real_alloc_size))) {
errno = ENOMEM;
return NULL;
}
// Mapping whole region with PROT_NONE
void *real = memory_map(real_alloc_size);
if (unlikely(real == NULL)) {
return NULL;
}
memory_set_name(real, real_alloc_size, name);
void *usable = (char *)real + guard_size;
size_t lead_size = align((uintptr_t)usable, alignment) - (uintptr_t)usable;
size_t trail_size = alloc_size - lead_size - usable_size;
void *base = (char *)usable + lead_size;
// Change protection to usable data with PROT_RAD|PROT_WRITE
if (unlikely(memory_protect_rw(base, usable_size))) {
memory_unmap(real, real_alloc_size);
return NULL;
}
//...
return base;
}
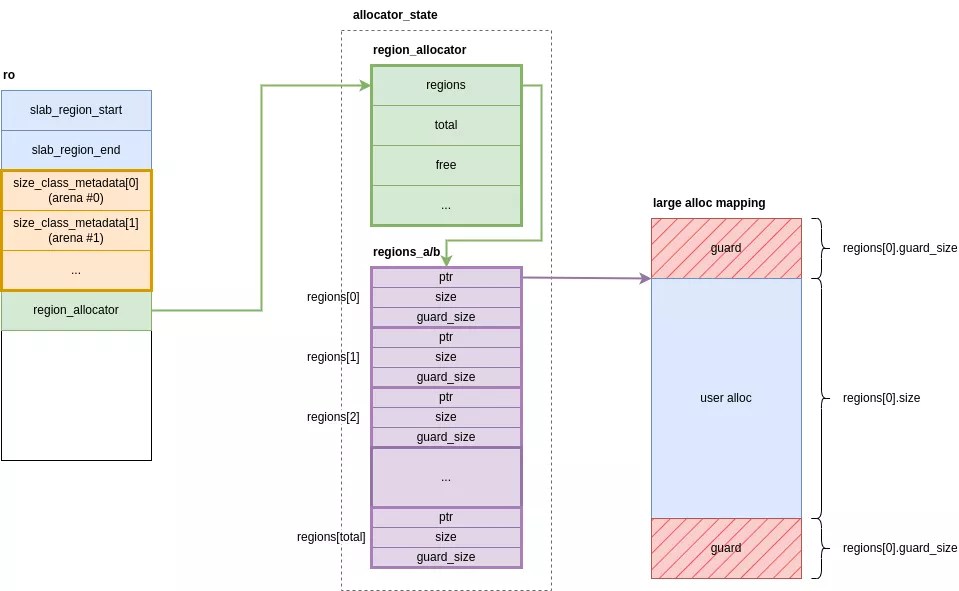
Si el mapeo es exitoso, se inserta una estructura que contiene la dirección, el tamaño utilizable y el tamaño de protección en una tabla hash de regiones. Esta tabla hash se implementa utilizando dos matrices de region_metadata structs: allocator_state.regions_a y allocator_state.regions_b (referenciado como ro.regions[0] y ro.regions[1]). Estas matrices tienen un tamaño estático y están reservadas en la inicialización.
Inicialmente, solo una parte de estas matrices es accesible (marcada como Leer/Escribir); el resto está protegido con PROT_NONE. A medida que el número de grandes asignaciones activas crece y excede los espacios de metadatos disponibles, la porción accesible de las matrices se duplica. Esta expansión utiliza un sistema de dos tablas: la tabla hash actual se copia a la tabla no utilizada anteriormente, que luego se convierte en la activa. La tabla antigua se vuelve a mapear PROT_NONE para hacerlo inaccesible.
static int regions_grow(void) {
struct region_allocator *ra = ro.region_allocator;
if (ra->total > SIZE_MAX / sizeof(struct region_metadata) / 2) {
return 1;
}
// Compute new grown size
size_t newtotal = ra->total * 2;
size_t newsize = newtotal * sizeof(struct region_metadata);
size_t mask = newtotal - 1;
if (newtotal > MAX_REGION_TABLE_SIZE) {
return 1;
}
// Select new metadata array
struct region_metadata *p = ra->regions == ro.regions[0] ?
ro.regions[1] : ro.regions[0];
// Enlarge new metadata elements
if (memory_protect_rw_metadata(p, newsize)) {
return 1;
}
// Copy elements to the new array
for (size_t i = 0; i < ra->total; i++) {
const void *q = ra->regions[i].p;
if (q != NULL) {
size_t index = hash_page(q) & mask;
while (p[index].p != NULL) {
index = (index - 1) & mask;
}
p[index] = ra->regions[i];
}
}
memory_map_fixed(ra->regions, ra->total * sizeof(struct region_metadata));
memory_set_name(ra->regions, ra->total * sizeof(struct region_metadata), "malloc allocator_state");
ra->free = ra->free + ra->total;
ra->total = newtotal;
// Switch current metadata array/hash table
ra->regions = p;
return 0;
}
Finalmente, metadatos de asignación, address + size + guard size, se inserta en la tabla hash actual ro.region_allocator->regions.
Para asignaciones grandes, que no están protegidas por MTE, las páginas de protección de tamaño aleatorio son la defensa principal contra desbordamientos. Si un atacante puede eludir esta aleatorización y tiene una vulnerabilidad de lectura/escritura fuera de límites con un desplazamiento preciso, corromper los datos adyacentes sigue siendo un escenario posible, aunque complejo.
Por ejemplo, una llamada a malloc(0x28001) crea los siguientes metadatos. Un tamaño de guardia aleatorio de 0x18000 bytes fue elegido por el asignador.
large alloc @ 0xc184d36f4ac8
ptr : 0xbe6cadf4c000
size : 0x30000
guard size: 0x18000Al inspeccionar los mapas de memoria del proceso, podemos ver que la gran asignación (que se alinea con un tamaño de 0x30000) está colocado de forma segura entre dos PROT_NONE regiones de guardia, cada una 0x18000 bytes de tamaño.
be6cadf34000-be6cadf4c000 ---p 00000000 00:00 0
be6cadf4c000-be6cadf7c000 rw-p 00000000 00:00 0
be6cadf7c000-be6cadf94000 ---p 00000000 00:00 0Free
Liberar una asignación grande es un proceso relativamente simple que utiliza el mismo mecanismo de cuarentena que las asignaciones pequeñas.
- Calcular hash de puntero: el hash del puntero se calcula para localizar sus metadatos.
- Recuperar metadatos: la estructura de metadatos de la asignación se recupera de la tabla hash actual (
ro->region_allocator.regions). - Cuarentena o desmapeo: el siguiente paso depende del tamaño de la asignación.
- Si el tamaño es menor que
0x2000000(32 MiB), la asignación se coloca en un sistema de cuarentena de dos etapas idéntico al de las asignaciones pequeñas (un caché de reemplazo aleatorio seguido de una cola FIFO). Esta cuarentena es global para todas las asignaciones grandes y se gestiona enro.region_allocator. - Si el tamaño es
0x2000000o mayor, o cuando una asignación se expulsa de la cuarentena, se desmapea inmediatamente de la memoria. Toda la región de memoria, incluida el área de datos y sus páginas de protección circundantes, se desmapea mediantemunmap() munmap((char *)usable - guard_size, usable_size + guard_size * 2);
Conclusión
Malloc endurecido es un asignador de memoria reforzado por la seguridad que implementa varios mecanismos de protección avanzados, en particular aprovechando la extensión de etiquetado de memoria (MTE) ARM para detectar y prevenir la corrupción de la memoria. Si bien ofrece una mejora con respecto al asignador scudo estándar, particularmente en comparación con uso después de la liberación vulnerabilidades, su verdadera fortaleza radica en su integración con GrapheneOS. Esta combinación logra un mayor nivel de seguridad que un dispositivo Android típico que utiliza scudo.
Además, el uso de canarios y numerosas páginas de protección complementa su arsenal, especialmente en dispositivos más antiguos sin MTE, al activar rápidamente excepciones en caso de acceso no deseado a la memoria.
Desde la perspectiva de un atacante, malloc endurecido reduce significativamente las oportunidades de explotar vulnerabilidades de corrupción de memoria:
- Desbordamiento de montón: malloc endurecido es relativamente similar al scudo, pero agrega páginas protectoras entre losas, lo que evita que un desbordamiento se extienda de una losa a otra. Sin embargo, con MTE habilitado, la protección se vuelve mucho más granular: incluso un desbordamiento dentro de una misma losa (de una ranura a otra) se detecta y bloquea sin necesidad de comprobar los canarios, lo que hace casi imposible la explotación de este tipo de vulnerabilidad.
- Uso después de la liberación: el mecanismo de doble cuarentena complica la reutilización de una región de memoria liberada pero no la hace del todo imposible. Sin embargo, MTE cambia radicalmente el acuerdo. El puntero y su región de memoria asociada están "etiquetados". Al ser liberada, esta etiqueta se modifica. Cualquier intento posterior de utilizar el puntero antiguo (con su etiqueta ahora no válida) muy probablemente generará una excepción, neutralizando el ataque. Para asignaciones grandes, que no están cubiertas por MTE, la estrategia es diferente: cada asignación está aislada por páginas de guarda y su ubicación en la memoria es aleatoria. Esta combinación de aislamiento y aleatorización hace que cualquier intento de reutilizar estas regiones de memoria sea difícil y poco confiable para un atacante.
Además, su implementación ha demostrado ser particularmente clara y concisa, facilitando su auditoría y mantenimiento.
Comparte este artículo